-
[통계학] Maximum Likelihood Estimator, MLE (최대우도법)Mathematics/statistics 2023. 11. 10. 19:23
(내용 계속 추가중)
* 기본 통계 용어 정리
1. Population 모집단
: 조사대상이 되는 집단.
2. sampling(표본추출)
- Population(모집단)으로부터 부분으로서의 sample(표본)을 selection(선택)하는 행위 또는 활동.
- 표본을 선택하는 과정을 표본추출 또는 표집이라고 한다.
3. sampling의 목적
: sample로부터 획득한 표본의 특성인 통계(sample statistic)를 사용하여 Population의 parameter(모수) 특성을 추론하는 데 있다.
4. statistics (통계량, 통계치)
: 표본에서 얻은 변수의 값을 요약하고 묘사한 것. 모집단의 모수는 대부분 통계치를 가지고 측정한다. 그러나 모집단을 완벽하게 반영하는 표본명단을 찾기는 거의 불가능하다.
5. parameter(모수)
- 모집단의 어떤 특성을 지칭하는 개념을 변수로 환원하여 측정한다고 할 때, 그 변수의 값을 모집단의 구성요소들에서 추출하여 요약/묘사한 값을 말한다. (모집단을 조사하여 얻을 수 있는 통계적 특성치)
- 어떤 확률분포를 나타내는데 사용되는 고유한 숫자를 의미. 이 숫자들은 해당 확률분포의 특성을 설명하고 제어하는 데 사용됨.
- 한 변수의 성격이 모집단에서 어떻게 나타나는지를 가리키는 것이다.
- 예를 들어 측정하려는 변수가 소득수준인 경우, 표본에서 구한 statistics인 평균 소득수준에 대응해서 전체 population에서 기대되는 평균소득수준이 parameter이다. 반면에 어떤 도시의 모든 가족들의 평균소득이나 시 population의 연령분포와 같은 것은 모두 parameter라 볼 수 있다.
6. bias (편의)
- 본래 실제의 상태와 다르게 나타나는 평균적 차이를 의미한다.
- 표본에 입각하여 추리하는 모집단의 추정치가 모수치의 진가와 계통적으로 차이가 나도록 만드는 오차를 말한다.
7. samplig distribution (표집분포)
: 동일한 크기의 표본을 반복해서 추출했을 때 각 표본의 statistics의 probability distribution(확률분포)이다.
8. sample distribution (표본분포)
: 실제 데이터 샘플에서 얻은 값들의 분포
9. 표본 평균, 표본 분산
:표본 크기(sample size)가 n일 때의 표집분포의 모수
위 정의를 종합해서 해석하자면, (표본 크기가 1인 표집분포) = (표본분포)라 할 수 있다.
* parameter를 추정하는 방법(MLE)
population(모집단)의 parameter를 알아내는 가장 좋은 방법은 전수조사이다. 그러나, 현실적으로 불가능하기에 sampling을 통해, parameter을 추정하는 방식을 택한다.
sample distribution은 normal distribution(정규분포)을 따르지 않더라도, central limit theorem(중심극한정리)에 의해 여러번의 sampling을 통해 구한 sample들의 statistics의 분포인 sampling distribution은 normal distribution을 따른다.

주황색 점들이 statistics이고, 주황색과 파란색 normal distribution 중에 어떤 것이 더 population의 parameter에 가까울까? (출처 : 밑에 참고.) sampling distribution는 normal distribution을 따르지만, 하나의 normal distribution으로 확정되진 않는다. 실제 population에 가까운 normal distribution을 어떻게 찾을까? (다시 말하면, statistics를 통해 구할 수 있는 parameter의 estimate(추정치) 중에 실제 population의 parameter에 가까운 것이 무엇인지를 묻는 것이다. 여기서 parameter의 종류 중, 평균값을 생각하면 생각하기 편하다.)
여러 방법이 있겠지만, statistics들을 가장 잘 표현해주는( statistics가 속할 확률이 가장 높은) parameter estimate가 실제 population의 parameter에 가까운 값일 것이다. 여기서, statistics가 속할 확률이 가장 높은 값을 계산하는 방법이 바로 MLE이다.
'속할 확률'이라는 말은 likelihood와 같고, 그 의미를 정확히 알기 위해서 likelihood에 대한 개념을 짚어보자.
* likelihood (가능도)
통계학에서 가능도(可能度, 영어: likelihood) 또는 우도(尤度)는 확률 분포의 모수가, 어떤 확률변수의 표집값과 일관되는 정도를 나타내는 값이다. 구체적으로, 주어진 표집값에 대한 모수의 가능도는 이 모수를 따르는 분포가 주어진 관측값에 대하여 부여하는 확률이다. 가능도 함수는 확률 분포가 아니며, 합하여 1이 되지 않을 수 있다. - 위키피디아 -
가능도에 대해 이해하기 위해서는 조건부확률을 알아야한다. P(x|θ)확률변수가 주어졌을 때 모수의 확률을 계산한 밀접한 관련이 있다. 조건부 확률을보통 확률이라하면, 대부분 이산확률을 떠올린다. 동전의 앞면이 나올 확률과 같이 이산확률은 해당 값에 대한 확률을 명확하게 표현할 수 있다.( sample distribution(sampling distribution이 아니다)은 normal distribution을 따르지 않는다.)
하지만 대한민국 남자의 키와 같이, 연속적인 값들은 확률을 계산할 때 분모가 무한한 값을 갖기에, 실제 확률을 계산하면 0에 가깝고, 확률을 계산하는 의미가 없다. (180cm에 대한 확률은 0이다.) 그러나, 키가 어느 구간에 속하는지에 대한 확률은 계산할 수 있다.
예를 들어, 171cm에서 190cm 중에 181cm~185cm를 뽑을 확률은 5/20이다. 이처럼 연속적인 값들의 구간에 속할 확률을 구하기 위해 만들어진 것이 probability density function, PDF (확률밀도함수)이다. 그리고 이를 그래프로 그린 것 중에 가장 잘 사용되는 것이 normal distribution(정규분포)이다. 그래프에서 특정 구간에 속한 넓이 = 특정 구간에 속할 확률이다.
그래프에서의 적분값이 특정 구간에 속할 확률이라면, y값은 likelihood(가능도)이다(특정 사건이 일어날 가능성).
* Maximum Likelihood Estimator, MLE
다시 parameter를 추정하는 설명으로 돌아가자. MLE를 사용하는 목적은 무엇일까?
MLE는 parameter estimate을 구하는 방법으로, 가능도를 최대로하는 parameter estimate가 population(모집단)의 parameter에 가장 가까운 estimate이라 할 수 있다. MLE 이름에서 알 수 있듯이, MLE는 statistics의 가능도의 최대값을 구하는 방법이다.
그렇다면 MLE는 어떻게 구할까? statistics 각각의 가능도를 모두 곱함으로써 각각의 statistics의 영향도를 반영하고, 곱한 가능도의 값을 최대로 하는 변수값을 구하기 위해 미분을 통해 값을 구한다. 보통, 수식의 편리성 때문에 로그 가능도를 사용한다.
이 과정을 수식적으로 표현하면 다음과 같다.
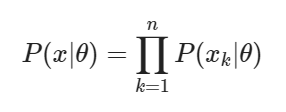
전체 표본집합의 likelihood function(결합확률밀도 함수) Θ는 parameter이다. log를 취하면, 로그 성질에 의해 곱셈이 덧셈이 된다.

log-likelihood function log-likelihood function의 최대값을 구하기 위해 Θ에 대해 편미분을 한다.

* 현실세계에서 MLE를 적용하는 상황을 생각해보자.
한국 남성의 키에 대한 평균(모수)을 알고자 한다. 전수조사를 통해 한국 남성 키를 알려면 막대한 비용이 발생할 것이다. 대신 한국 남성들 중 몇 명의 샘플 데이터를 통해 한국 남성 키에 대한 정보(모수)를 추정할 수 있다. 상식적으로 한국 남성 키에 대한 실용적인 정보(모수)는 '평균'이라는 사실은 뻔한데, 모수에 대한 개념을 확실히 공부하기 위해서 그런 '상식'이 없는 상태라고 가정해보자. 그렇다면 한국 남성들 중 몇 명의 키를 측정한, 샘플 데이터를 통해 구할 수 있는 parameter(모수)는 무엇일까?
앞서 정리한 parameter에 대한 설명을 다시 보자면, "어떤 확률분포를 나타내는데 사용되는 고유한 숫자"이다. 다시 말하면, 확률분포에 따라 parameter가 다르다. 즉, 추정할 수 있는 모수가 무엇인지 알기 위해, 확률분포를 가정하는 과정이 필요하다. ( 확률분포 종류에 따른 다양한 모수는 아래 <더보기>에 정리해놨다.>
더보기확률분포 종류에 따른 다양한 모수들.
'~'의 의미는 '확률변수 X가 ~ 다음의 확률분포를 따른다.'이다.
- 정규분포 (Normal Distribution):
- 모수: 평균(μ), 분산(σ^2)
- 이항분포 (Binomial Distribution):
- 모수: 시행 횟수(n), 성공 확률(p)
- 포아송분포 (Poisson Distribution):
- 모수: 평균 발생 횟수(λ)
- 지수분포 (Exponential Distribution):
- 모수: 비율(λ, 양수)
- 카이제곱분포 (Chi-square Distribution):
- 모수: 자유도(degrees of freedom, df)
- 로그-정규분포 (Log-Normal Distribution):
- 모수: 로그-평균(μ), 로그-표준편차(σ)
- 베타분포 (Beta Distribution):
- 모수: 모수 α, β (양수)
자연적인 현상의 대부분은 정규분포를 따르기 때문에 키도 정규분포를 따를 것이 자명하나, 앞서 말했듯 우리는 확률분포를 모른다는 가정에서 출발해보자. 그렇다면, 샘플이 정규분포를 따를지 안 따를지 모르는 상황인데, 무조건 정규분포를 따르게끔 해줄 수 있다면 어떨까? 평균과 분산을 구하고자 한다면 아주 강력한 도구일 것이다. 그 도구가 바로, '중심극한정리'다.
중심극한정리이란,
"어떤 모집단 을 가정하고 이때 표본이 어느 일정량(수준)이상이 될때 표본평균 분포는 $에 수렴(근사)하는 정규분포가 된다."
샘플이 정규분포를 따르지 않더라도, 그 샘플의 statistics(통계량)은 정규분포를 따른다는 것을 증명한 것이다. 다시말해, 중심극한 정리에 따르면, sampling distribution(표집분포)은 모집단의 평균과 같은 정규분포를 따른다. 표집분포는 "동일한 크기의 표본을 반복해서 추출했을 때 각 표본의 statistics의 probability distribution(확률분포)"이다. 예를들어, 전국에서 남성 키 샘플을 30개 뽑아서 평균을 내는 행위를 또 100번 반복하면 그 statistics(이 예시에서는 표본평균)는 모집단의 평균과 같은 정규분포를 따른다는 것이다.
그렇다면 중심극한정리에 의해 모평균과 표집분포를 통해 구한 평균은 일치한다는 것을 알았다.
정답은 표본크기만 충분하다면, 모집단이 정규분포를 따르든 안 따르든 모평균과 표집분포에서 추정한 평균은 근사적으로 일치한다고 할 수 있다.
* 용어 및 개념을 정리하고 가자.
"전국에서 남성 키 샘플을 30개 뽑아서 평균을 내는 행위를 100번 반복하면 그 statistics는 정규분포를 따른다는 것이다." 에서
- "샘플 30개" 라는 것은 "표본의 크기(sample size) = 30"을 뜻하고
- 샘플 30개로 뽑아서 만든 평균은 표본평균(sample mean)이라고 한다. (기호는 $\bar{X}$)
- 또한 샘플 30개로 만든 표본평균은 매 추출마다 값이 다를 것이다. 고로, 각각의 표본평균은 여러가지 값을 가질 수 있는 확률변수로 생각할 수 있다. 앞서 설명한대로 중심극한정리에 의해, 표본평균의 PDF(probability density function, 확률밀도함수)는 정규분포이다.
- 정규분포는 평균과 분산으로 표현하는데, 모집단의 정규분포는 N(m,$\sigma^2$)이다.
- 모집단의 확률분포가 정규분포이면 $\bar{X}$는 n(sample size)에 관계없이 정규분포 N(m,$\frac {\sigma^2} {n})을 따른다.
- 모집단의 확률분포가 정규분포가 아니더라도 표본의 크기 n이 충분히 크면 표본평균을 확률변수로 갖는 PDF는 근사적으로 정규분포 (m,$\frac {\sigma^2} {n})를 따른다.
* 자, 그렇다면 이제 진짜 모수를 추정해보자.
전국에서 남성 키 샘플을 30개 뽑아서 평균을 내는 행위를 또 100번 반복해서 구한 것은 중심극한정리를 설명하기 위한 상황 설정이었고, 이제 실제 목표였던, 전국 남성 키에 대한 평균(m)을 추정해보자. 우리는 모집단의 PDF가 정규분포를 따를 것이라고 가정한다. (자연 현상은 대부분 정규분포를 따른다는 사전지식을 이용)
현재 모수(m)가 얼마인지 안 정해져있고, 샘플을 뽑아서 그 샘플들을 통해 모수일 가능성이 가장 높은 모수를 추정해야한다.
그렇다면 정규분포에서 n개의 표본을 독립추출한다고 했을 때,
$$PDF=p(x;\theta)= f_{X_i}(x_i;\theta) = \frac{1}{\sigma\sqrt{2\pi}} \exp\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right) , \,\,i=1, \cdots, n $$ 라고 표현할 수 있다.
그러면 독립적으로 추출한 전체 n개의 표본에 대한 우도함수(likelihood)는 아래와 같이 표현될 것이다.
$$ P(x|\theta) = \prod_{i=1}^{n}f_{X_i}(x_i;\theta)= \prod_{i=1}^{n}\frac{1}{\sigma\sqrt{2\pi}} \exp \left( -\frac{(x_i-\mu)^2}{2\sigma^2} \right) $$
양변에 log를 취해서 log likelihood function $L(\theta|x)$를 구하면, 아래와 같이 전개된다.
$$L(\theta|x) = \log P(x|\theta) = \sum_{i=1}^{n}\log\frac{1}{\sigma\sqrt{2\pi}}\exp\left(-\frac{(x_i-\mu)^2}{2\sigma^2}\right) $$
위 식을 정리해주면 아래와 같다.
$$ =\sum_{i=1}^{n} \left[ -\frac{(x_i-\mu)^2}{2\sigma^2}-\log(\sigma) - \log(\sqrt{2\pi}) \right] $$
이제 MLE를 적용한다. $L(\theta|x)$를 모평균 $\mu$에 대해 편미분하고 미분계수가 0이 되게 하는 $\mu$값을 구한다. 미분계수가 0이 될 때 likelihood가 최대가 되고, 이때의 $\mu$값이 우리가 찾고자하는 모수이다.
$$\frac{\partial L(\theta|x)}{\partial \mu} = -\frac{1}{2\sigma^2}\sum_{i=1}^{n}\frac{\partial}{\partial \mu}\left(x_i^2-2x_i\mu+\mu^2\right) $$
$$ \frac{\partial L(\theta|x)}{\partial \mu} =-\frac{1}{2\sigma^2}\sum_{i=1}^{n}\left(-2x_i+2\mu\right)$$
$$=\frac{1}{\sigma^2}\sum_{i=1}^{n}(x_i-\mu) = \frac{1}{\sigma^2}\left(\sum_{i=1}^{n}x_i-n\mu\right) = 0 $$
따라서 모평균의 estimate(추정량)은 $ \hat{\mu}$이고, 아래와 같다.
$$ \hat{\mu} = \frac{1}{n}\sum_{i=1}^{n}x_i $$
우리는 위에서 $\hat{\mu}$는
$ \hat{\mu} = \frac{1}{n}\sum_{i=1}^{n}x_i = \bar{x}$이므로 이는 표본평균을 의미한다.
이는 모수를 추정하기 위해 샘플을 뽑았는데, 그 샘플들의 평균(표본평균)이 모수의 여러 후보들 중 가장 가능성 높은 estimate이라는 의미이다.
말로 다시 풀어쓰자면, 전국의 남성 키의 평균을 추정하기 위해 n개의 샘플을 뽑아서 n개의 샘플에 대한 가장 큰 가능도를 갖는 모수를 추정하고자 했고, 모집단이 정규분포를 따른다는 사실을 바탕으로 가장 큰 가능도를 가질 때의 모수 추정치를 계산해냈다. 결과적으로 그 추정치는 n개의 샘플들의 평균이었다.
MLE를 머신러닝에서 어떻게 이용하는가? 이것은 다음에 계속...
* 참고
최대우도법에 대해 가시적으로 설명한 유튜브 영상의 블로그
https://bookdown.org/mathemedicine/Stat_book/probability-vs-likelihood.html#-------likelihood
'Mathematics > statistics' 카테고리의 다른 글
불편추정량, 편의추정량 (1) 2023.12.03 [통계학] 통계적 모델링을 위한 기초 통계학 (0) 2023.08.30