-
[Python 자료구조 #정렬과 탐색2] 순차탐색, 이진탐색, 보간탐색, 해싱Programming 기초/Python 2023. 5. 24. 18:41
* 탐색(searching)
- 탐색은 레코드(record)의 집합에서 원하는 레코드를 찾는 작업이다.
- 테이블(table) : 보통 이러한 레코드들의 집합
- 탐색키(search key) : 레코드들이 서로를 구별하여 인식하기 위해 가지고 있는 키(key)
- 탐색은 테이블에서 원하는 탐색키를 가진 레코드를 찾는 작업이다.
- 탐색에서는 테이블을 구성하는 방법에 따라 효율이 달라진다. 맵 또는 딕셔너리는 자료를 저장하고 탐색키를 이용해 원하는 자료를 빠르게 찾을 수 있도록 하는 탐색을 위한 자료구조를 말한다.
* 맵(map)
- 맵(map)은 엔트리(entry)라고 불리는 키를 가진 레코드(keyed recod)의 집합이다.
- 엔트리는 두 개의 필드를 가진다.
- 키(key) : 영어 단어나 사람의 이름과 같은 레코드를 구분할 수 있는 탐색키
- 값(value) : 영어 단어의 의미나 어떤 사람의 주소와 같은 탐색키와 관련된 값
- 결국 맵은 키-값의 쌍(key, value)으로 이루어진 엔트리의 집합이다. 파이썬은 내장 자료형으로 딕셔너리를 제공하는데, 이것은 자료구조 맵을 구현한 하나의 예이다.
* 간단한 탐색 알고리즘
1. 순차 탐색(sequential search)
- 정렬되지 않은 테이블에서도 원하는 레코드를 찾을 수 있다. 테이블의 각 레코드를 처음부터 하나씩 순서대로 검사하여 원하는 레코드를 찾는 탐색 방법이다.
- 시간 복잡도 O(n)
# 탐색 대상 리스트 A, 탐색 키 key, 탐색 범위 low, high def sequential_search(A, key, low, high) : # 순차 탐색 for i in range(low, high+1) : # i : low, low+1, ... high if A[i].key == key : # 탐색 성공하면 return i # 인덱스 반환 return None # 탐색 실패하면 None 반환2. 이진 탐색(binary search)
- 이진 탐색은 테이블의 중앙에 있는 값을 조사하여 찾는 항목이 왼쪽에 있는지 오른쪽에 있는지를 판단한다.
- 이진 탐색은 각 단계에서 탐색 범위가 반으로 줄어든다. n개의 자료 중 탐색 범위가 1이 될 때(최악의 경우)의 탐색 횟수를 k라 하면, n/2^k=1이 된다. 즉, k=log_2 n이므로 이진탐색의 시간 복잡도는 O(log_2 n)이다.
- 테이블이 킷값을 기준으로 정렬되어 있는 경우에 사용가능하기 때문에 데이터의 삽입이나 삭제가 빈번한 응용에는 적합하지 않다.
def binary_search(A, key, low, high): # 순환적 알고리즘을 이용한 이진 탐색 if low <= high: #항목들이 남아 있으면(종료 조건) middle = (low + high) // 2 # 정수 나눗셈 if key == A[middle].key: # 탐색 성공 앞에 key는 변수이고 .key는 key()모듈이다. return middle # 탐색성공 elif key < A[middle].key: # 왼쪽 부분리스트 탐색 return binary_search(A, key, low, middle - 1) else: # 오른쪽 부분리스트 탐색 return binary_search(A, key, middle + 1, high) return None # 탐색 실패middle은 배열의 인덱스이므로 정수가 되어야 한다. 파이썬에서는 두 가지 나눗셈 연산자 /와 //를 제공하는데, /연산의 결과는 실수(float)객체이고, // 연산의 결과는 정수(int)라는 것을 명심.
def binary_search_iter(A, key, low, high) : # 반복 구조로 구현한 이진 탐색 while (low <= high) : middle = (low + high) // 2 if key == A[middle].key: return middle elif (key > A[middle].key): low = middle + 1 else: high = middle - 1 return None3. 보간 탐색(interpolation search)
- 이진탐색의 일종으로 사전에서 단어를 찾을 때와 같이 탐색키가 존재할 위치를 예측하여 탐색하는 방법이다.
- 이진 탐색에서 탐색 위치 middle은 (low+high)/2로 계산했지만 보간 탐색에서는 탐색 값과 위치는 비례한다는 가정에서 탐색 위치를 결정할 때 찾고자 하는 키값이 있는 곳에 근접하도록 가중치를 주는 방법으로 탐색위치를 결정한다.
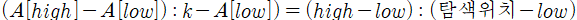
보간 탐색은 찾는 값과 위치가 비례한다고 가정한다. 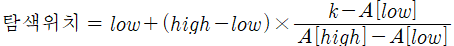
# 보간탐색 # 이진탐색 함수에서 middle 계산 코드만 다음과 같이 수정하면 된다. middle = int(low+(high-low)*(key-A[low].key)/(A[high].key-A[low].key))* 해싱(hashing)
- 키값에 산술적인 연산을 적용하여 레코드가 저장되어야 할 위치를 직접 계산하는 것
- 충돌이 일어나지 않는 이상적인 상황에서의 시간 복잡도는 O(1). 실제 해싱의 탐색 연산은 O(1)보다는 느리다.
1. 해시 함수(hash function)
- 해싱에서 키값으로부터 레코드가 저장될 위치(해시 주소(hash address))를 계산하는 함수
- 좋은 해시 함수는 충돌이 적어야 하고, 주소가 테이블에서 고르게 분포되어야 하며, 계산이 빨라야 한다.
- 제산 함수 : 나머지 연산%(nodular)을 이용하는 것. h(k)=k mod M. 해시 테이블의 크기 M은 소수(prime number)를 선택한다. 1과 자기 자신만을 약수로 가지는 수라면 k%M이 0에서 M-1로 골고루 사용하는 값을 만들어낼 수 있기 때문이다.
- 폴딩(floding) 함수 : 탐색키가 해시 테이블의 크기보다 더 큰 정수일 경우에 사용된다. 탐색키를 몇 개의 부분으로 나누어 이를 더하거나 비트별 XOR와 같은 부울 연산을 이용하는 것. 탐색키를 여러 부분으로 나눈 값들을 더하는 이동 폴딩(shift folding)과 이웃한 부분을 거꾸로 더해 해시 주소를 얻는 경계 폴딩(boundary folding)이 대표적이다.
- 중간 제곱 함수 : 탐색키를 제곱한 다음, 중간의 몇 비트를 취해서 해시 주소를 생성하는 방법이다. 제곱한 값의 중간 비트들은 대개 탐색키의 모든 자리의 숫자들과 관련이 있다. 따라서 두 키값에서 몇 개의 자리가 같더라도 서로 다른 해싱 주소를 갖게 된다. 탐색키를 제곱한 값의 중간 비트들은 보통 비교적 고르게 분산된다.
- 비트 추출 방법 : 해시 테이블의 크기가 M=2^k일 때 탐색키를 이진수로 간주하여 임의의 위치의 k개의 비트를 해시 주소로 사용하는 것. 간당한 방법이지만, 탐색키의 일부 정보만을 사용하므로 해시 주소의 집중 현상이 일어날 가능성이 많다.
- 숫자 분석 방법 : 키의 각 위치에 있는 숫자 중에서 편중되지 않는 수들을 해시 테이블의 크기에 적합한 만큼 조합하여 해시 주소로 사용하는 방법이다. 예를 들어 학번이 201912345와 같이 부여되면 앞의 4자릿수는 편중되므로 사용하지 않고 나머지 자리의 수들을 조합하여 해시 주소로 사용한다.
- 탐색키가 문자열인 경우 : 보통 각 문자에 정수를 대응시켜 바꾸게 된다.
2. 해시 테이블(hash table)
- 해시 함수에 의해 계산된 위치에 레코드를 저장한 테이블.
- 해시 테이블은 M개의 버킷(bucket)으로 이루어지는 테이블이고, 하나의 버킷은 여러 개의 슬롯(slot)을 가진다.
- 하나의 슬롯에는 하나의 레코드가 저장된다.
3. 해시 주소(address)
- 키값 key가 입력되면 해시 함수로 연산한 결과 h(key)가 해시 주소가 된다. 이를 인덱스로 사용하여 항목에 접근한다.
4. 충돌(collision)
- 버킷이 충분하지 않으면 경우에 따라 서로 다른 키가 해시함수에 의해 같은 주소로 계산되는 상황
5. 동의어(synonym)
- 충돌을 일으키는 키들
6. 오버플로(overflow)
- 충돌이 슬롯 수보다 더 많이 발생하는 상황. 해당 버킷에 더 이상 항목을 저장할 수 없게 된다.
7. 이상적인 해싱
- 충돌이 절대 일어나지 않는 경우로, 해시 테이블의 크기를 충분히 크게하면 가능하지만 메모리가 지나치게 많이 필요하다. 실제의 해싱에서는 충돌과 오버플로가 빈번하게 발생하므로 시간 복잡도는 이상적인 경우의 O(1)보다는 떨어지게 된다.
* 선형 조사에 의한 오버플로 처리
- 선형 조사법(linear probing)은 해싱 함수로 계산된 버킷에 빈 슬롯이 없으면 그 다음 버킷에서 빈 슬롯이 있는지를 찾는 방법이다. 이때 비어 있는 공간을 찾는 것을 조사(probing)라고 한다.
- 선형 조사법은 해시 테이블의 k번째 위치인 ht[k]에서 충돌이 발생했다면 다음 위치인ht[k+1]부터 순서대로 비어 있는지를 살피고(조사), 빈 공간이 있으면 저장한다.
- 군집화(clustering) : 한번 충돌이 발생한 위치에서 항목들이 집중되는 현상. 선형 조사법은 간단하지만 오버플로가 자주 발생하면 군집화 현상에 따라 탐색의 효율이 크게 저하될 수 있다.
* 이차 조사법(quadratic probing)
- 군집화 문제를 완화시키기 위한 방법으로 충돌이 발생하면 다음에 조사할 위치를 다음 식에 의해 결정하는 방법이다.
(h(k)+i*i)% M for i = 0, 1, ... , M-1
- 이 방법은 군집화 현상을 완화시킬 수 있는데, 물론 2차 집중 문제를 일으킬 수는 있찌만 1차 집중처럼 심각한 것은 아니다. 2차 집중의 이유는 동일한 위치로 사상되는 여러 탐색키들이 같은 순서에 의하여 빈 버킷을 조사하기 때문이다. 이것은 이중 해싱법으로 해결할 수 있다.
* 이중 해싱법(double hashing)
- 재해싱(rehashing)이라고도 불린ㄴ다. 충돌이 발생해 저장할 다음 위치를 결정할 때, 원래 해시 함수와 다른 별개의 해시 함수를 이용하는 방법이다. 선형조사법과 이차조사법은 해시 함수 값이 같으면 다음 위치도 같게 된다.
- 이중 해싱법은 해시 함수 값이 같더라도 탐색키가 다르면 서로 다른 조사 순서를 갖도록 하여 2차 집중을 완화할 수 있다.
* 체이닝(chaining)에 의한 오버플로 처리
- 체이닝은 하나의 버킷에 여러 개의 레코드를 저장할 수 있도록 하는 방법으로, 버킷은 보통 연결 리스트로 구현한다.
- 체이닝을 연결 리스트로 구현한다면 삽입하는 노드를 맨 끝이 아니라 맨 앞에 추가하는 것이 훨씬 효율적이다.
- 만약 파이썬의 리스트를 이용한다면 append()연산을 이용해 리스트의 맨 뒤에 추가하는 것이 더 효율적일 것이다.
* 탐색 방법들의 성능 비교
- 적재 밀도(loading density) 또는 적재 비율(loading factor) : 해시 테이블이 얼마나 채워져 있는지를 나타낸다.

- α가 0이면 해시 테이블은 비어있다. α의 최댓값은 충돌 해결 방법에 따라 달라진다. 선형 조사법에서는 테이블이 가득차면 모든 버킷에 하나의 항목이 저장되므로 1이 된다. 체인법에서는 저장할 수 있는 항목의 수가 해시 테이블의 크기를 넘어설 수 있기 때문에 α는 최댓값을 가지지 않는다.
탐색방법 탐색 삽입 삭제 순차탐색 O(n) O(1) O(n) 이진탐색 O(log_2 n) O(n) O(n) 이진탐색트리 균형트리 O(log_2 n) O(log_2 n) O(log_2 n) 경사트리 O(n) O(n) O(n) 해싱 최선의 경우 O(1) O(1) O(1) 최악의 경우 O(n) O(n) O(n) * 맵의 응용 : 나의 단어장
맵을 구현할 수 있는 방법은 여러 가지가 있다.
- 리스트를 이용해 순차탐색 맵을 구현하는 방법
- 리스트를 정렬해서 이진탐색 맵을 구현하는 방법
- 선형조사법으로 해시 맵을 구현하는 방법
- 체이닝으로 해시 맵을 구현하는 방법
이들 중에서 순차탐색 맵과 체이닝을 이용한 해시 맵을 구현해보자.
1. 맵 ADT를 직접 구현해서 만들기
맵은 엔트리의 집합이므로 엔트리 클래스가 필요하다. 엔트리에는 키(key)와 값(value)이 필요하다.
class Entry: def __init__( self, key, value ): self.key = key self.value = value def __str__( self ): return str("%s:%s"%(self.key, self.value) )클래스에 _ _str_ _ 함수를 추가하면 객체를 필요시 문자열로 변환할 수 있다. 예를 들어, 파이썬의 print()함수는 인수로 문자열을 요구하는데, Entry의 객체 e가 있을 때 print(e)를 호출하면 객체 e를 _ _ str_ _ 함수를 이용해 문자열로 변환한 후 이를 화면에 출력한다.
2. 리스트를 이용한 순차탐색 맵
class SequentialMap: # 순차탐색 맵 def __init__( self ): self.table = [] # 맵의 레코드 테이블 def size( self ): return len(self.table) # 레코드의 개수 def display(self, msg): # 보기 좋게 출력 print(msg) for entry in self.table : print(" ", entry) def insert(self, key, value) : # 삽입 연산 self.table.append(Entry(key, value)) # 리스트의 맨 뒤에 넣는 것이 효율적(O(1)) def search(self, key) : # 순차 탐색 연산 pos = sequential_search(self.table, key, 0, self.size()-1) # 앞서 구현한 순차 탐색 함수(O(n)) 호출 if pos is not None : return self.table[pos] else : return None def delete(self, key) : # 삭제 연산 : 항목 위치를 찾아 pop for i in range(self.size()): if self.table[i].key == key : self.table.pop(i) returnmap = SequentialMap() map.insert('data', '자료') map.insert('structure', '구조') map.insert('sequential search', '선형 탐색') map.insert('game', '게임') map.insert('binary search', '이진 탐색') map.display("나의 단어장: ") print("탐색:game --> ", map.search('game')) print("탐색:over --> ", map.search('over')) print("탐색:data --> ", map.search('data')) map.delete('game') map.display("나의 단어장: ") ---------------------------------------------------------- 나의 단어장: data:자료 structure:구조 sequential search:선형 탐색 game:게임 binary search:이진 탐색 탐색:game --> game:게임 탐색:over --> None 탐색:data --> data:자료 나의 단어장: data:자료 structure:구조 sequential search:선형 탐색 binary search:이진 탐색 나의 단어장: {'data': '자료', 'structure': '구조', 'sequential search': ' 선형 탐색', 'game': '게임', 'binary search': '이진 탐색'} 탐색:game --> 게임 탐색:data --> 자료 나의 단어장: {'data': '자료', 'structure': '구조', 'sequential search': ' 선형 탐색', 'binary search': '이진 탐색'}3. 체이닝을 이용한 해시 맵
class Node: def __init__(self, data, link=None): self.data = data self.link = link class HashChainMap: # 해시 체인 맵 def __init__(self, M): self.table = [None] * M # 크기 M인 테이블을 먼저 만듦 self.M = M def hashFn(self, key): #사용할 해시 함수 sum = 0 for c in key: # 문자열의 모든 문자에 대해 sum = sum + ord(c) # 아스키 코드 값을 모두 더함 return sum % self.M def insert(self, key, value): #(key, value) 입력 idx = self.hashFn(key) # 해시 주소 계산 self.table[idx] = Node(Entry(key, value), self.table[idx]) # 전단 삽입 # 마지막 줄을 다음과 같이 풀어서 기술할 수 있음. # entry = Entry(key, value) (1) 엔트리 생성 # node = Node(entry) (2) 엔트리로 노드를 생성 # node.link = self.table[idx] (3)노드의 링크필드 처리 # self.table[idx] = node (4) 테이블의 idx 항목 : node로 시작 def search(self, key): idx = self.hashFn(key) node = self.table[idx] while node is not None: if node.data.key == key: return node.data node = node.link return None # 삭제연산 : # 단순연결리스트를 사용하기 때문에 삭제할 노드의 선행노드(befor)를 알아야 한다. def delete(self, key): idx = self.hashFn(key) node = self.table[idx] before = None while node is not None: if node.data.key == key: if before == None: self.table[idx] = node.link else: before.link = node.link return before = node # before 갱신 node = node.link # 노드 갱신 def display(self, msg): print(msg) for idx in range(len(self.table)): node = self.table[idx] if node is not None: print("[%2d] -> " % idx, end="") while node is not None: print(node.data, end=" -> ") # 연산자 중복함수(__str__)사용 node = node.link print()map = HashChainMap(13) map.insert("data", "자료") map.insert("structure", "구조") map.insert("sequential search", "선형 탐색") map.insert("game", "게임") map.insert("binary search", "이진 탐색") map.display("나의 단어장: ") print("탐색:game --> ", map.search("game")) print("탐색:over --> ", map.search("over")) print("탐색:data --> ", map.search("data")) map.delete("game") map.display("나의 단어장: ") ------------------------------------------------------------ 나의 단어장: [ 3] -> sequential search:선형 탐색 -> [ 7] -> binary search:이진 탐색 -> game:게임 -> data:자료 -> # 두 번의 충돌이 발생한다. [ 8] -> structure:구조 -> 탐색:game --> game:게임 탐색:over --> None 탐색:data --> data:자료 나의 단어장: [ 3] -> sequential search:선형 탐색 -> [ 7] -> binary search:이진 탐색 -> data:자료 -> [ 8] -> structure:구조 ->4. 파이썬의 딕셔너리를 이용한 구현
d = {} # 딕셔너리(맵) 객체를 만듦 d["data"] = "자료" # 맵에 새로운 엔트리를 삽입 d["structure"] = "구조" d["sequential search"] = "선형 탐색" d["game"] = "게임" d["binary search"] = "이진 탐색" print("나의 단어장:") print(d) # 맵 출력 if d.get("game"): # 탐색. 키값이 'game'인 엔트리가 있으면 True 없으면 False print("탐색:game --> ", d["game"]) # 엔트리의 값(value)을 반환 if d.get("over"): print("탐색:over --> ", d["over"]) if d.get("data"): print("탐색:data --> ", d["data"]) d.pop("game") # 항목 삭제 print("나의 단어장:") print(d) -------------------------------------------------------------------------------------------------------------------- 나의 단어장: {'data': '자료', 'structure': '구조', 'sequential search': '선형 탐색', 'game': '게임', 'binary search': '이진 탐색'} 탐색:game --> 게임 탐색:data --> 자료 나의 단어장: {'data': '자료', 'structure': '구조', 'sequential search': '선형 탐색', 'binary search': '이진 탐색'}'Programming 기초 > Python' 카테고리의 다른 글
[Python 자료구조 #트리2] 모르스 코드 결정트리 (0) 2023.05.25 [Python 자료구조 #트리1] 이진 트리, 전위/중위/후위/레벨 순회 (1) 2023.05.25 [Python 자료구조 #정렬과 탐색1] 선택정렬, 삽입정렬, 버블정렬, 정렬 응용한 집합 (0) 2023.05.23 [Python 자료구조 #연결리스트3] 이중연결리스트 : 연결된 덱 (0) 2023.05.23 [Python 자료구조 #연결리스트2] 원형연결리스트 : 연결된 큐 (0) 2023.05.23