-
[DL for VS #8] 배치 정규화Machine Learning/Deep Learning for Vision Systems 2023. 4. 17. 03:31
4.9 배치 정규화
입력층에 이미지를 입력하기 위한 데이터의 전처리에서 정규화를 사용했었다.(아래 요약 참고)
4.3.2 데이터 전처리(신경망에 입력되기 전에 이루어지는 것들)
회색조 이미지 변환 – 계산 복잡도를 경감시킬 수 있다.
이미지 크기 조절 – 신경망의 한계점 중 하나는 입력되는 모든 이미지의 크기가 같아야 한다.
데이터 정규화 – 데이터에 포함된 입력 특징(이미지의 경우 픽셀값)의 배율을 조정해서 비슷한 분포를 갖게 함.
데이터 강화 – 데이터 강화를 데이터 전처리로도 활용할 수 있다.이미 추출된 특징을 정규화하면 은닉층도 마찬가지로 정규화의 도움을 받을 수 있다. '추출된 특징'은 변화가 심하므로 정규화를 통해 신경망의 학습 속도와 유연성을 더욱 개선할 수 있다. 이런 기법을 배치 정규화(batch normalization, BN)라고 한다. 배치 정규화는 공변량 시프트 문제를 해결하기 위해 도입된 것이다.
4.9.1 공변량 시프트(covariate shift) 문제
데이터셋 X를 레이블 y에 매핑하도록 모델을 학습한 후 X의 분포가 변화한 경우를 공변량 시프트라고 한다. 공변량 시프트가 발생하면 모델을 다시 학습해야 할 수도 있다.
예를 들면, 흰색 고양이로 치워친 훈련 데이터로 학습된 고양이 분류기에 흰색이 아닌 다른 색 고양이 이미지를 분류할 때 좋은 성능이 나오지 않는 경우로, 이러한 입력데이터 분포의 변화를 공변량 시프트라고 한다.
4.9.2 신경망에서 발생하는 공변량 시프트
4개의 층을 가진 MLP를 예로 들면, L3의 관점에서 L1의 파라미터(w,b) 변화에 의해 L3층의 입력에 해당하는 L2층의 출력값들이 변화하고 있다. 즉, 은닉층 내부에서 공변량 시프트가 발생하는 것이다.

4.9.3 배치 정규화의 원리
세르게이 이요페(Sergey Ioffe)와 크리스티안 세게디(Christian Szegedy)가 2015년 논문에서 공변량 시프트를 완화하기 위한 대책으로 배치 정규화를 제안했다. 배치 정규화는 각 층의 활성화 함수 앞에 다음 연산을 추가하는 방법이다.
- 입력의 평균을 0으로 조정
- 평균이 0으로 조정된 입력을 정규화
- 연산 결과의 배율 및 위치 조정
* 배치 정규화의 수학적 원리
1. 현재 입력 중인 미니배치의 입력값의 평균을 0으로 조정하려면 입력의 평균과 표준편차를 계산해야한다.
m이 배치 내 데이터 수일 때 미니배치의 평균(mu_B)과 표준편차(sigma_B)는 다음과 같이 계산한다.
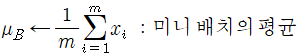

2. 입력을 정규화한다. 여기서 x(hat)은 평균이 0이며 정규화된 입력이다.
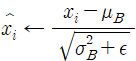
새로운 변수 epsilon이 추가되었다. 이 변수는 일부 추정치에서 sigma가 0일 경우 0으로 나누는 것을 피하기 위한 충분히 작은 값이다(일반적으로 10^-5 정도 사용).
3. 배율 및 위치를 조정한다. 정규화된 입력에 gamma를 곱해 배율을 조정하고 beta를 더해 위치를 조정한 y_i를 계산한다.

배치 정규화를 적용하면 신경망에 2개의 새로운 파라미터 gamma와 beta가 도입된다. 따라서 최적화 알고리즘이 가중치와 함께 이 두 가지 파라미터를 수정한다. 학습 초기에 최적의 배율과 오프셋을 찾기까지는 약간 학습 속도가 느리게 느껴지지만 최적의 값을 찾고 나면 학습이 눈에 띄게 빨라진다.
4.9.4 케라스를 이용해서 배치 정규화 구현하기
케라스에서는 정규화된 결과를 다음 층에 전달할 수 있도록 은닉층 뒤에 배치 정규화층을 추가하는 형태로 구현된다.
다음은 신경망에 배치 정규화층을 추가한 예다.
from keras.models import Sequential from keras.layers import Dense, Dropout from keras.layers.normalization import BatchNormalization # 배치 정규화를 구현한 BatchNormalization 클래스를 임포트한다. model = Sequential() # 모델을 초기화한다. model.add(Dense(hidden_units, activation='relu')) #첫 번째 은닉층을 모델에 추가한다. model.add(BatchNormalization()) # 첫 번째 은닉층 뒤에 배치 정규화층을 추가해서 배치 정규화를 적용한다. # 드롭아웃을 함께 적용하려면 배치 정규화 계산에 드롭아웃된 뉴런이 누락되지 않도록 배치 정규화층 뒤에 드롭아웃츠을 배치하는 것이 좋다. model.add(Dropout(0.5)) model.add(Dense(units, activation='relu')) # 두 번째 은닉층을 모델에 추가한다. model.add(BatchNormalization()) #두 번째 은닉층 뒤에 배치 정규화층을 추가한다. model.add(Dense(2, activation='softmax')) # 출력층을 모델에 추가한다.정리하자면 배치 정규화는 은닉층 유닛의 출력이 항상 표준 분포를 따르도록 강제하는 방법이며, 이 과정 역시 학습 대상이 되는 두 파라미터 gamma와 beta가 제어한다.
4.10 프로젝트 : 이미지 분류 정확도 개선하기
GitHub - moelgendy/deep_learning_for_vision_systems: This repository accompanies the book "Deep Learning for Vision Systems".
This repository accompanies the book "Deep Learning for Vision Systems". - GitHub - moelgendy/deep_learning_for_vision_systems: This repository accompanies the book "Deep Learning fo...
github.com
* 프로젝트 개요
1. 의존 라이브러리 임포트
2. 학습을 위한 데이터 준비
- 케라스 라이브러리를 이용해서 데이터 내려받기
- 훈련 데이터, 검증 데이터, 테스트 데이터로 분할하기
- 데이터 정규화
- 정답 데이터에 원-핫 인코딩 적용하기
3. 모델 구조 정의. 일반적인 합성곱층 및 풀링층 외에 다음 층을 추가한다.
- 신경망의 표현력을 증가시키기 위해 층수 늘리기
- 드롭아웃층
- 합성곱층에 L2 규제화층 추가하기
- 배치 정규화층
4. 모델 학습하기
5. 모델 평가하기
6. 학습 곡선 그리기'Machine Learning > Deep Learning for Vision Systems' 카테고리의 다른 글
[DL for VS #7] 신경망 하이퍼파라미터 튜닝 (0) 2023.04.13 [DL for VS #6] 성능 지표 - 정확도, 혼동 행렬, 정밀도, 재현율, F-점수, 시각화 예제 (0) 2023.04.12 [DL for VS #5] 컬러 이미지 합성곱 연산 실습 (0) 2023.04.12 [DL for VS #4] CONV kernel, stride, padding, pooling, dropout (0) 2023.04.12 [DL for VS #3] 최적화 알고리즘-(배치, 확률적, 미니배치)경사하강법, 역전파 알고리즘 (1) 2023.04.08